

Introduction

Figure 1. Process Flow of Biopharmaceutical Manufacturing
As noted in earlier posts, because biopharmaceutical manufacturing is dependent upon production within living cells, it is more complex and prone to variability than production of conventional ‘small-molecule‘ / ‘chemical‘ pharmaceuticals. The number of steps involved as well as the complexity of each step, present many opportunities for variability to enter the production process. In fact, minimizing this variability is perhaps the greatest day-to-day challenge that manufacturers face even from production of one batch to another.
The vast majority of biopharmaceuticals are proteins produced via animal cell culture using recombinant DNA (rDNA) technology. The production process of these recombinant proteins provides an excellent model through which to highlight both the process of, and hurdles faced in biopharmaceutical manufacturing. The inherent difficulty of animal cell culture, is further compounded by the need for costly ingredients, complex equipment and very tightly-managed conditions. Additional costs can be incurred due process failures resulting from the high sensitivity of cell cultures, bacterial contamination, genetic instability, equipment faults and even operator error.
In this series of posts on ‘Biopharmaceutical Manufacturing‘, the process has been arbitrarily broken into 10 steps as seen in Figure 1 above but in theory it could have been described in either less or more steps depending on the approach taken. This first post, ‘Biopharmaceutical Manufacturing 1‘ introduces the two part series on manufacturing biopharmaceuticals but also the first 5 steps of the process. The second post, ‘Biopharmaceutical Manufacturing 2‘ will elaborate upon the latter 5 steps when published shortly.

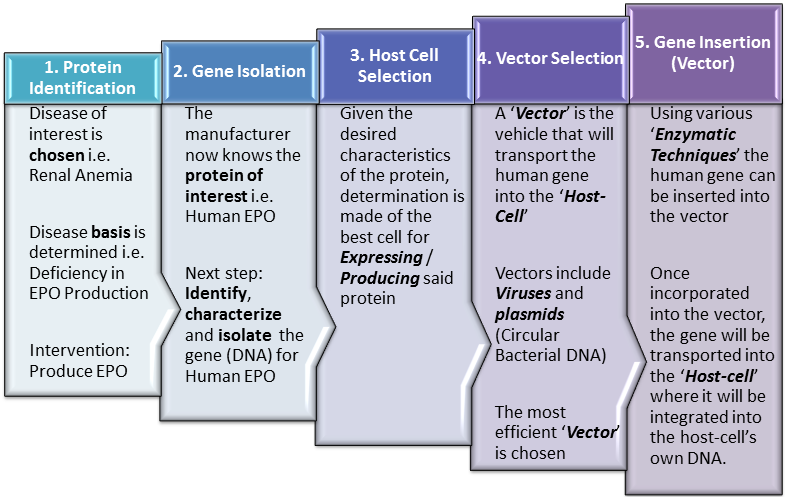
Figure 2. Initial Steps in Recombinant Protein Manufacture
Click to review Process Flow
Step 1. Protein Identification
In Step 1 the manufacturer begins by deciding upon the medical problem / indication that they wish to address. Once that is determined, a logical next step would be assessment of the molecular basis of the disease. If linked to or affected by a protein, this protein becomes the target of interest for research and development efforts.
For example, in kidney failure, the function of these vital organs is compromised. One result of this, is that the kidneys no longer produce enough of the glycoprotein hormone ‘erythropoietin‘. This glycoprotein is responsible for stimulating the production of red blood cells (RBCs) / erythrocytes in the bone marrow. The deficiency of this hormone, reduces production of new RBCs and markedly reduces the life-span of existing RBCs. Since erythrocytes are responsible for transporting Oxygen around the body, if not corrected, patients with kidney failure suffer from chronic anaemia leading to fatigue and in time, heart failure and premature death among other complications.
One solution to this problem is therefore to produce erythropoietin externally and introduce it into the body to supplement the kidneys’ declining ouput. To summarize this step, having linked the ailment to an identified protein deficiency, the manufacturer has identified a protein of interest on which to focus R&D efforts.
Click to review Process Flow Click to review Initial Steps
Step 2. Gene Isolation
In the same way that bricks are the basic units of construction for buildings, amino acids (AAs) are the building blocks of proteins. So every protein is formed by connecting individual AAs together in long chains which eventually take on complex 3-dimensional configurations based on intrinsic and environmental factors. This unique 3-dimensional configuration is fundamental to the protein’s ability to carry out its function.
Significantly, each of the 20 amino acids from which all proteins are built, is coded for in the genetic material common to all life on earth, namely DNA (Deoxyribonucleic Acid). In fact, DNA holds not only the codes for the amino acids but also for the sequence in which each is to be included when building every known protein. In other words, the blueprint or instruction manual by which every living organism on earth produces proteins is found in its DNA.
Share this Post
At Step 2 therefore, the biopharmaceutical manufacturer must isolate or engineer (design) the genetic sequence (in the form of DNA) that codes for the desired protein. This specific sequence of genetic material (DNA) is known as the ‘gene‘ for that protein and is unique to it. Furthermore, there may be different variants of a given protein, so the manufacturer must ensure that they isolate or engineer the precise gene related to the specific protein variant they desire. Where such methods are used to create new gene combinations that previously did not exist in nature, they are described as ‘Recombinant Techniques‘ and fittingly, the DNA sequences are called ‘Recombinant DNA (rDNA)‘. In practice this often involves introducing genes from one species into another.
The gene can be acquired by extracting the corresponding DNA from existing cells or as noted above, can be built (engineered) in a lab using specific nucleic acid bases (The basic units of DNA). It is worthwhile to mention here, that while erythropoeitin is found in many animals, the manufacturer would likely best be served by isolating or engineering the gene for the specific human variant. This is because the immune system can detect when non-human substances and proteins in particular, enter the body. In such cases, the body’s own defense mechanisms for destroying the offending protein, can be harmful to the individual. So at all times, it is best to work with human (or humanized – engineered to appear more human) proteins.
Click to review Process Flow Click to review Initial Steps
Step 3. Host Cell Selection
Having selected or engineered the desired gene, the manufacturer must then determine the type of cell most likely to yield large quantities of the desired protein in the ideal 3-dimensional configuration. Production of the protein is based on instructions coded in the gene and is termed ‘expression‘ of the gene. The act of protein chain formation which occurs as the amino acids are linked ‘head-to-tail’ is called ‘Translation‘. In fact, the protein is said to be ‘translated’ from an intermediary form of genetic material called ‘Messenger Ribonucleic Acid‘ or ‘mRNA‘ which is produced based upon the original DNA template.
Notably, the type of cell in which the gene is placed and in which the protein is subsequently expressed, determines the types and extent of changes that will be made to the protein after the chain of amino acids (AAs) has been completely ‘translated’. Because these changes occur after all the amino acids have been joined together in the protein chain, they are described as ‘post-translational‘ modifications. Importantly, bacterial cells are unable to carry out many of the post-translational modifications which occur in the human body. A notable example of post-translational modification which bacteria such as E. Coli cannot effect, is the addition of carbohydrate chains, a process otherwise known as ‘Glycosylation‘. For some proteins, post-translational modification is very important to their ability to function and so selection and use of mammalian cells is critical in spite of the increased complexities associated with working with them in cell cultures.
For example, the types and quantity of carbohydrate chains added after the protein backbone is completed will vary widely depending on whether a bacterial cell such as E. Coli is used as opposed to a mammalian cell such as Chinese Hamster Ovary (CHO) cells.
Click to review Process Flow Click to review Initial Steps
Step 4. Vector Selection
Based on the type of ‘Host-cell‘ selected, an appropriate ‘Vector‘ must be chosen in turn to transport the ‘gene of interest‘ into the cell. Vector selection is also important because specific vectors demonstrate varying levels of efficiency in ‘Transfecting‘ different types of host cell. Use of a poorly matched vector therefore can lead to a low percentage of cells actually acquiring the gene of interest and without the gene, the protein of interest will not be produced. This would mean that the manufacturer would have engaged up to that point in a very costly yet unproductive exercise.
Examples of vectors include:
- Plasmids which are circular loops of bacterial DNA known to confer resistance to bacteria by transferring resistance genes from one bacterium to another.
- Retroviruses (Viruses which contrary to the usual approach, actually store genetic information in RNA (Ribonucleic Acid) and produce DNA (Deoxyribonucleic Acid) once inside their target cell. This is the reverse of what most living organisms do, hence the designation ‘retro’-virus)
- Bacteriophages (Plant viruses)
- Direct injection of DNA
Click to review Process Flow Click to review Initial Steps
Step 5. Gene Insertion
Once the vector has been selected, the gene of interest must be inserted into it and successfully integrated into its own genome (repository of genetic information / DNA). This is achieved using various techniques which may or may not include the use of enzymes. Enzymes used in this phase of the process to join the DNA coding for our protein to the DNA found in plasmids include:
- Restriction Enzymes
- Ligases
Click to review Process Flow Click to review Initial Steps
For more information take a look at ‘Biopharmaceutical Manufacturing Part 2‘ which explores the latter steps of the process and download additional content on the biopharmaceutical manufacturing process from the ‘CBp Downloads‘ Section.
CLICK HERE to view Downloads on Pharmaceutical Manufacturing from CaribbeanBiopharma